
Zeyu Wang, Yao-Hui Li | 01 May 2025
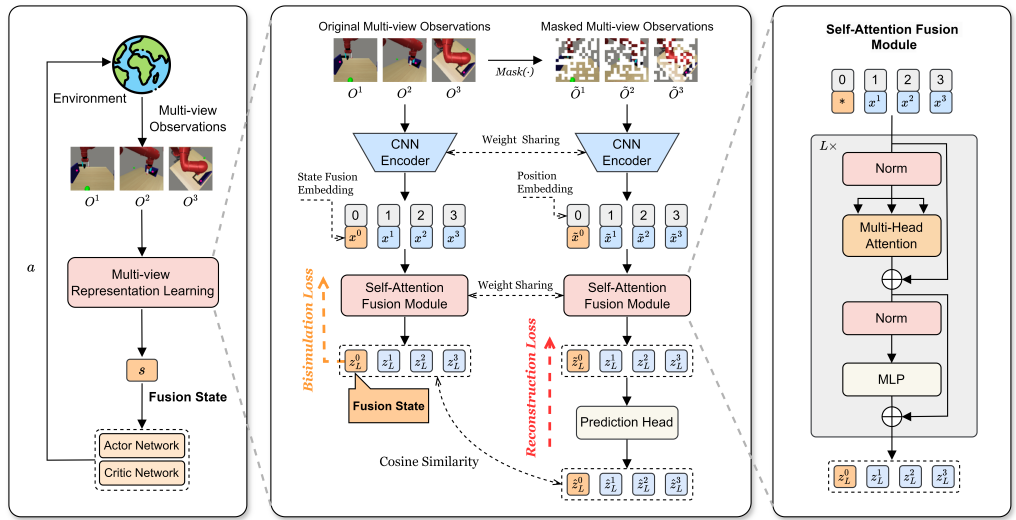
In this study, we designed a novel Multi-View Reinforcement Learning (MVRL) framework, Multi-view Fusion State for Control (MFSC), to address the challenge of learning compact and task-relevant representations from multi-view observations, particularly when facing redundancy, distractors, or missing views. This is achieved by firstly incorporating bisimulation metric learning into the MVRL pipeline, and secondly introducing a multiview-based mask and latent reconstruction auxiliary task to effectively exploit shared information and significantly improve the...
Ruixiang Sun, Hongyu Zang | 01 May 2024
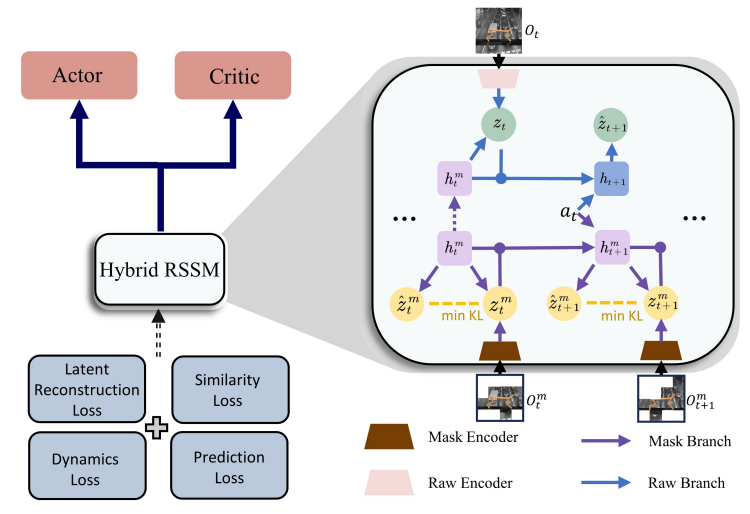
In the cooperation of our lab and DreamFold AI, we designed a novel Visual Model-Based Reinforcement Learning (MBRL) approach to address the issue of non-essential noise in pixel-based observations by applying a spatio-temporal masking strategy and a bisimulation principle, enabling the world model to effectively capture endogenous, task-specific features. Furthermore, we developed a Hybrid Recurrent State-Space Model (HRSSM) structure to enhance state representation robustness, resolving instabilities commonly encountered during the...
Hongyu Zang | 19 October 2022
In the cooperation of our lab, Mila, and MSR-Montreal, we designed a novel DRL framework to address the issue of designing the goal of the agent for high-dimensional sensory inputs by learning factorial representations of goals and processing the resulting representation via a discretization bottleneck. We first test our method in Color-MNIST dataset to support the idea that we can learn factorized or compositional representationsin. Color-MNIST example to demonstrate factorized representations; reconstructing...

Hongyu Zang | 09 December 2021
In this project, we focus on learning invariant representation for Reinforcement Learning by extending the previous work of bisimulation metric. We devise Simple State Representation (SimSR) operator. SimSR enables us to design a stochastic approximation method that can practically learn the mapping functions (encoders) from observations to latent representation space. We test our agents on three visual tasks: visual control tasks, visual control tasks whose background is disturbed by natural videos, and...

Jie Huang | 20 September 2021
Inverse Reinforcement Learning (IRL) is mainly for complex tasks where the reward function is difficult to formulate. In general, IRL is to learn the reward function from the expert demonstrations, which can be understood as explaining the expert policy with the reward function we learned. When learning policies based on optimal sequence samples is needed, we can combine inverse reinforcement learning and deep learning to improve the accuracy of the reward function...

Li Zhang | 26 February 2020
In the cooperation of our lab and Ubisoft, we designed a novel DRL framework and applied it to train agents in Rabbids: Journey To The West, a party game of Rabbids series, which is a famous title presented by Ubisoft. To test our agents, we organized competitions, in which three human-players formed a team and collaborated to compete with a single agent trained by our approach. This event attract many people to...
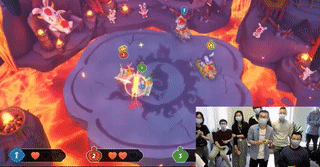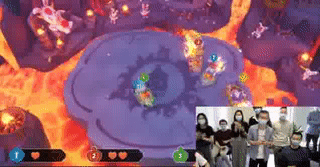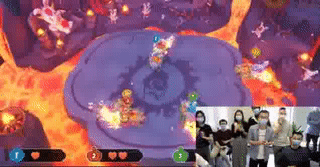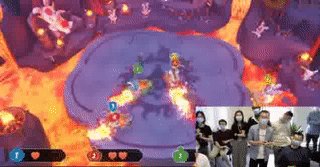
Li Zhang | 18 February 2020
Most existing DRL approaches focus on leveraging the deep neural network structure to approximate the value function via a trial-and-error learning process, but insufficiently address explicit planning computation as in the conventional model-based approaches. We proposed Universal Value Iteration Networks (UVIN) to combine model-free learning and model-based planning in common RL setting to improve long-term reasoning and inference. Performance on Minecraft Spatially-variant maze Minecraft is a popular sandbox video game that allows...

Pengfei Zhu | 14 April 2017
Most of Deep Reinforcement Learning (DRL) methods focus on Markov Decision Process (MDP). Partially Observable Markov Decision Process (POMDP) is an extension of MDP. It naturally models planning tasks with uncertain action effects and partial state observability, however, finding an optimal policy is notoriously difficult. Inspired by belief state update based on Bayes’ theorem, we proposed Action-specific Deep Recurrent Q-Network (ADRQN) to improve DRL in POMDP. Performance on Atari Performance on Doom...
